Первый раз я увидел трассировку агента в Claude Code — и завис минуты на три. Там прямо в терминале было видно, как модель разговаривает сама с собой: «Мне нужно найти файл конфига. Вызову list_files. Получил список — вижу config.json. Открою его. Читаю... нашёл нужное поле. Теперь обновлю.» Это был не просто вывод — это было мышление агента в реальном времени. Я привык думать про AI как про "спросил — ответил". А тут машина планировала, делала что-то, смотрела на результат и корректировала план. Оказалось, за этим стоит конкретный паттерн с названием ReAct. И он объясняет, как работает практически любой AI-агент сегодня.
Статья для тех, кто пользуется Claude Code, настраивает n8n-агента или просто хочет понять, почему у агентов иногда "едет крыша". Если уже знакомы с LangGraph и пишете агентов на Python — переходите сразу к секции «Где ReAct ломается». Если не знакомы с промптингом вообще — начните с полного гида по промпт-инжинирингу, там фундамент.
Что такое ReAct-паттерн и при чём тут рассуждение
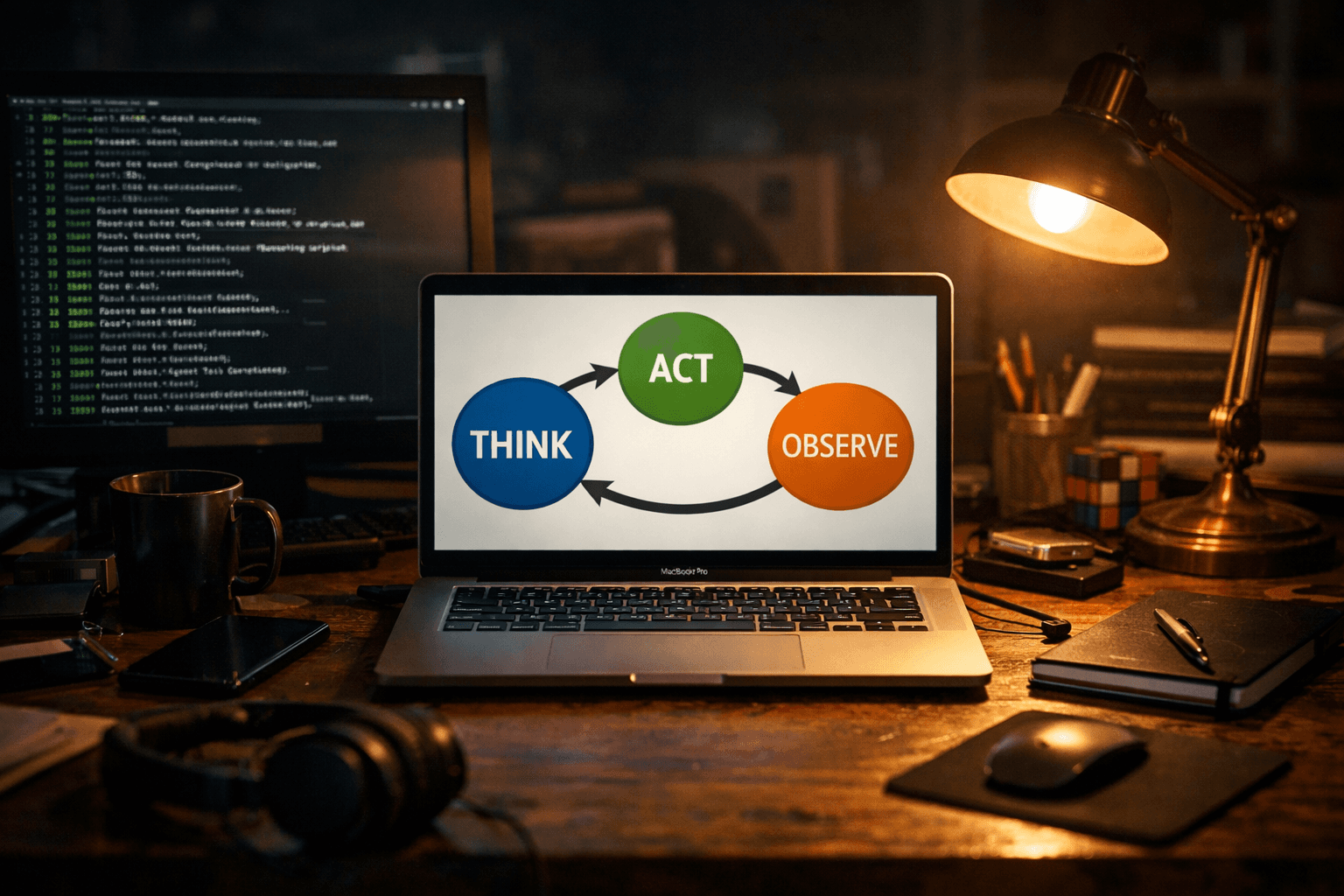
ReAct (Reasoning + Acting) — паттерн работы AI-агента, при котором модель чередует шаги рассуждения (Thought), действия (Action) и наблюдения (Observation). Именно этот цикл лежит в основе Claude Code, n8n-агентов, ChatGPT с инструментами и большинства автономных AI-систем.
Придумали его не вчера: статья Яо и коллег из Google и Princeton вышла в 2022 году. Но тогда это была академическая идея. В 2025-2026 она стала стандартной архитектурой для продакшен-агентов — всё потому, что появились нормальные инструменты реализации (LangChain, LangGraph, Claude Code) и модели стали достаточно умными, чтобы реально делать что-то полезное в петле.
Аналогия, которая мне помогла: ReAct — это как работает мозг при незнакомой задаче. Ты не решаешь её с первого выстрела. Ты думаешь — пробуешь — смотришь что вышло — думаешь снова. Сломалась кофемашина: думаю, что может быть не так → снимаю крышку и смотрю → вижу сгоревший предохранитель → думаю, где купить новый → иду в магазин → возвращаюсь с запчастью. Это не магия. Это итеративное решение задачи с обратной связью от мира.
AI-агент без ReAct — это как ответить на вопрос, не имея возможности ничего проверить. Как оракул: получил вопрос, выдал ответ, надейся что правильный. ReAct даёт агенту возможность действовать, получать обратную связь и корректировать курс.
Цикл Thought → Action → Observation: как это выглядит изнутри
Три компонента цикла — и каждый делает своё:
Thought (мысль) — агент рассуждает вслух. Что известно, чего не хватает, какой следующий шаг. Эти рассуждения не видны пользователю (или видны как "extended thinking"), но они формируют весь дальнейший план. Без этого шага агент просто угадывает.
Action (действие) — агент вызывает инструмент. Поиск в интернете, запрос к базе данных, чтение файла, вызов API. Конкретное действие в реальном мире. Именно здесь агент выходит за пределы своих знаний — берёт свежую информацию, которой нет в обучающих данных.
Observation (наблюдение) — результат действия. Агент получает ответ инструмента и добавляет его в контекст. Это не просто "данные пришли" — это новая точка для следующего рассуждения.
Вот живая трассировка. Задача: «Найди последнюю цену акций Apple и сравни с ценой месяц назад».
Thought: Мне нужна текущая цена AAPL и цена 30 дней назад.
Начну с текущей — вызову поиск финансовых данных.
Action: search("AAPL stock price today")
Observation: Apple Inc. (AAPL) — $178.32, обновлено 15 минут назад.
Thought: Хорошо, текущая цена есть. Теперь нужна цена месяц назад.
Поищу исторические данные.
Action: search("AAPL stock price February 26 2026")
Observation: AAPL 26 февраля 2026 — закрытие $163.10.
Thought: Есть обе точки. Считаю изменение:
(178.32 - 163.10) / 163.10 × 100 = +9.3%.
Могу отвечать пользователю.
Answer: За последний месяц Apple выросла на 9.3% — с $163.10 до $178.32.
Это не псевдокод — именно так выглядит логинг реального ReAct-агента. Три шага повторяются столько раз, сколько нужно. Иногда это один цикл, иногда — двадцать.
Инфо
Каждый раз когда агент "вызывает инструмент" — это Action в ReAct-цикле. Поиск в интернете в ChatGPT, чтение файла в Claude Code, HTTP-запрос в n8n — все они следуют одной архитектуре. Разные оболочки, один паттерн.
Почему ReAct — это основа почти всех AI-агентов
Когда смотришь на популярные агентные системы изнутри, везде видишь одно и то же.
Claude Code — при выполнении задачи явно показывает Thought-блоки перед каждым вызовом инструмента. Модель пишет «Мне нужно проверить зависимости» — и только потом вызывает read_file. Это буквально ReAct с видимым мышлением. Я писал подробнее про то, как устроен Claude Code — там весь агентный цикл строится именно на этом.
ChatGPT с инструментами — то же самое, только thinking-блоки скрыты. Когда GPT-4o решает проверить что-то через поиск или вызывает Code Interpreter, внутри происходит ReAct-цикл. Просто вы его не видите.
n8n AI-агент — там есть отдельный нод "AI Agent", который работает по ReAct-схеме. Нода принимает задачу, выбирает нужный инструмент (из тех, что ты подключил), получает результат, снова рассуждает. Конфигурируется через системный промпт — туда можно влиять на поведение агента в Thought-шаге.
LangChain create_react_agent — это буквально ReAct в одном вызове. Библиотека существует именно потому, что паттерн стал стандартом.
Почему все пришли к одному решению? Потому что альтернативы хуже для большинства задач. Chain-of-Thought (цепочка рассуждений) — только думает, не действует. Без инструментов модель работает только со своими знаниями. Прямой вызов инструментов без рассуждений — агент не понимает контекст и делает случайные действия. ReAct = думать + делать + смотреть. Это минимальная рабочая архитектура для агента.
Важный бонус: ReAct снижает галлюцинации. Модель не "прыгает к ответу" из обучающих данных — она итерирует через реальные инструменты. Если информации нет — ищет. Если нашла что-то другое — переосмысляет.
Чем ReAct отличается от Chain-of-Thought — и когда он хуже
Сравниваю три основных подхода:
| Метод | Суть | Инструменты | Когда работает лучше |
|---|---|---|---|
| Chain-of-Thought (CoT) | Рассуждение перед ответом | Нет | Математика, логика, задачи на знания |
| ReAct | Рассуждение + действия с инструментами | Да | Поиск информации, работа с файлами, API |
| Plan-and-Execute | Сначала план, потом выполнение | Да | Длинные многошаговые задачи |
Chain-of-Thought (CoT, «цепочка мыслей» — техника, при которой модель явно расписывает ход решения перед ответом) лучше ReAct в одном сценарии: когда вся нужная информация уже есть в контексте. Задача по математике, логическая головоломка, вопрос на знания — там инструменты не нужны. CoT дешевле и быстрее.
ReAct проигрывает в нескольких ситуациях:
- Скорость. Каждый Action — это отдельный запрос к инструменту. Если нужно 10 действий — 10 дополнительных задержек.
- Стоимость. Больше токенов на Thought-шаги, больше API-вызовов.
- Ошибки накапливаются. Если на третьем шаге агент получил неверный Observation — он может пойти по неправильному пути и не вернуться.
Есть ещё Plan-and-Execute: агент сначала строит полный план, потом выполняет шаг за шагом. Подходит для сложных многоэтапных задач, где важна последовательность. Дороже и медленнее, но меньше отклоняется от цели. ReAct — он же "реактивный" — принимает решения по ходу, что гибко, но может уйти в сторону.
Совет
Практическое правило: если задача требует актуальных данных или работы с внешними системами — ReAct. Если вся информация уже есть в промпте — CoT дешевле и быстрее. Не надо использовать агента там, где хватит хорошего промпта.
Где ReAct ломается: типичные проблемы петли агента
За несколько месяцев работы с агентами я несколько раз наблюдал, как ReAct-петля идёт вразнос. Вот паттерны, которые встречаются чаще всего.
Бесконечная петля. Агент получает Observation, который не даёт нужной информации, думает, что нужно попробовать иначе, делает новый Action — и снова облом. Петля крутится, пока не упрётся в лимит шагов или токены. Хорошие реализации ставят max_iterations — обычно 10-20 шагов, после которых агент останавливается и говорит "не смог". Плохие реализации — молча жрут деньги.
Галлюцинированные инструменты. Модель решает использовать инструмент, которого нет в списке доступных. Пишет в Thought: "Вызову get_user_profile(id=123)" — но такого инструмента нет. Зависит от качества системного промпта: чем чётче описаны доступные инструменты, тем реже происходит.
Потеря цели. Через несколько шагов агент забывает оригинальный вопрос и начинает решать промежуточную подзадачу как основную. Чем длиннее контекст — тем выше риск. Это прямое следствие контекст-инжиниринга: если правильно не закрепить цель в контексте, она вымывается.
Неверные Observation. Инструмент вернул ошибку или пустой ответ — агент может интерпретировать это как "данных нет" и двигаться дальше, не заметив проблему. Хорошие агенты явно обрабатывают ошибки инструментов — это настраивается через системный промпт.
Есть и ситуативный сбой: когда контекст заполнен лишним, модель начинает "терять нить" гораздо раньше. Это лечится правильным управлением thinking-токенами и чисткой контекстного окна между шагами.
Внимание
Петля агента без ограничений — это прямые расходы. Один безлимитный ReAct-цикл с поиском может потратить $1-2 на один запрос, если что-то пошло не так. Всегда ставьте max_iterations и добавляйте в системный промпт инструкцию "если не можешь решить за N шагов — скажи об этом пользователю".
Как ReAct связан с контекст-инжинирингом
Это самое нетривиальное. ReAct — это не просто "как агент действует". Это ещё и "как агент строит свой контекст на ходу".
Каждый Observation добавляется в контекстное окно. После пяти шагов там уже лежат результаты пяти вызовов инструментов плюс пять Thought-блоков. После десяти — соответственно. Контекст разбухает быстро.
Хороший контекст-инжиниринг для агентов — это умение управлять этим ростом. Есть несколько подходов: сжимать старые Observation (выбрасывать детали, оставлять выводы), изолировать задачи (давать подагентам только нужный кусок контекста), явно фиксировать прогресс в "памяти" (чтобы агент не терял из виду, что уже сделано).
Один паттерн, который реально работает: в системном промпте явно говорить агенту, в каком формате описывать свои Thought. Например: "В каждом шаге рассуждения сначала укажи, какова цель, затем что уже известно, затем что нужно проверить." Это структурирует мышление и делает контекст более компактным. Тот же принцип, что и в MCP-инструментах — у каждого инструмента должна быть чёткая спецификация, что он делает и что возвращает.
ReAct без хорошего контекст-инжиниринга — это как умный сотрудник с плохой рабочей памятью: правильно рассуждает, но к десятому шагу забывает, с чего начинал.
ReAct — не хайп. Это рабочая архитектура, которая уже несколько лет стоит за инструментами, которыми мы пользуемся каждый день. Claude Code, n8n, ChatGPT с поиском — все работают по одной схеме: думай, делай, смотри, думай снова.
Понимание этого паттерна даёт конкретную практическую пользу. Знаешь, что агент думает перед каждым действием — формулируй задачи так, чтобы цель была явной в начале. Знаешь, что Observation влияет на следующий Thought — описывай ожидаемый результат, не только сам запрос. Знаешь, что контекст разбухает с каждым шагом — не давай агенту задачи, которые требуют 30 итераций там, где хватит одной хорошей.
В общем: ReAct объясняет, почему агенты иногда тупят и как с этим работать. Это не магия и не чёрный ящик. Это три буквы на повторе.


